第9話 雑誌よ、ウェブの血となれ肉となれ! 構造化による知の体系
HTML5 Book Story Episode 9 :
今年の1月から「小さく」スタートしたマガジンもあと数日で、2ヵ月になります。7月の正式オープンまでは、個人サイトとして更新を続けていきますが、少しずつ骨格が出来上がってきました。ストアの開設、ウェブキャストのシーズン2、そして新たに、ワークショップのトライアルも開始し、それぞれが密接に連携するように調整しながら進めています。
いずれも、迅速かつ「小さく」実践していますので、ストアも初期費用を必要としないDLmarket、ワークショップのトライアルも「出張」だけに絞っています。スタッフが募集できる7月までは、このペースです。
図:2014年2月25日に更新
さて、今回はワークショップ[トライアル]の一つ「Adobe Muse CCの基礎を完全習得」の実習「ランディングページに構造化データを付加する」の紙面掲載です。
Google、Yahoo!、Microsoft(Bing)の3社が推進する「schema.org(スキーマドットオーグ)」および、「microdata(マイクロデータ)」を使った構造化データのマークアップについて解説しています。マークアップ済みコードをMuseの画面に挿入して、段落スタイルを適用するだけの作業なので、15分程度ですが、「マシンアプローチ」の概念を理解していただくために取り入れました。
講義15分、実習15分の内容ですが、記事化してみると、そこそこのボリュームになってしまったようです。
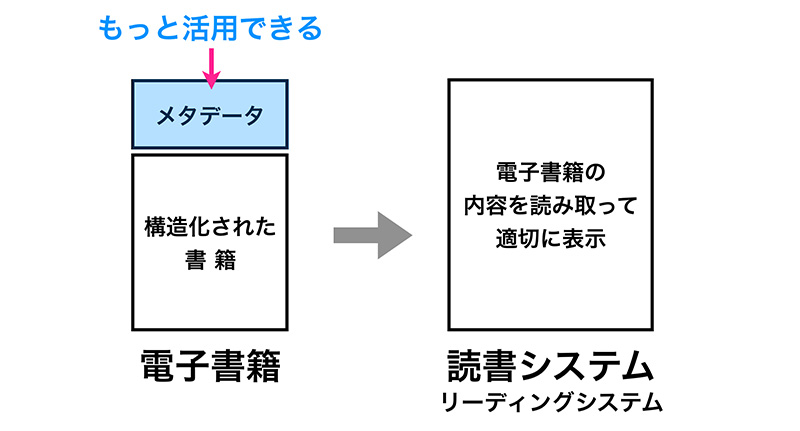
電子書籍とは「本に関するメタデータ+構造化データ」
電子書籍という言葉を定義するのはなかなか難しいものです。EPUBやKindleフォーマットで作られた電子出版物を「電子書籍」と呼ぶこともありますし、Wordで執筆した小説をPDFファイルにして「電子書籍」と呼んでもよいわけです。そもそも一般的に語られている「電子書籍」には、漫画や雑誌なども含まれているのですから、ほんとに曖昧なものです。
ただ、私は電子出版の仕事をしている身として、狭義の電子書籍[eBook]を「本に関するメタデータ+構造化データ」と定義しています。専門的な言い方になりますが、コンピュータープログラムにも本の内容を伝えられる「マシンリーダブル」なデータになっているかどうかで、線を引くことにしています。
コンピューター用語の「メタ(meta)」は、「一段高いレベル」といった意味を持っています。電子書籍はデジタルデータですが、メタデータはその上位に付加されますので、ちょっとややこしいですが「データのデータ」ということになります。EPUBなどの電子書籍フォーマットは、本に関するメタデータの記述が必須になっており、たんにコンテンツ(HTMLファイルや画像ファイル)をまとめたパッケージとは内包している情報が異なります。
ただ、商業出版は、学術ネットワークのように「共有」を前提に事を進めることはできません。著作権保護のためにDRMを適用したり、企業として利潤を追求するため、ストアと対の専用クライアント(電子書籍を読むためのビューワー)を開発します。やむを得ないことですが、どうしても顧客囲い込みのサービスになってしまうのです。
せっかくのメタデータも有効活用できていないのが残念です。
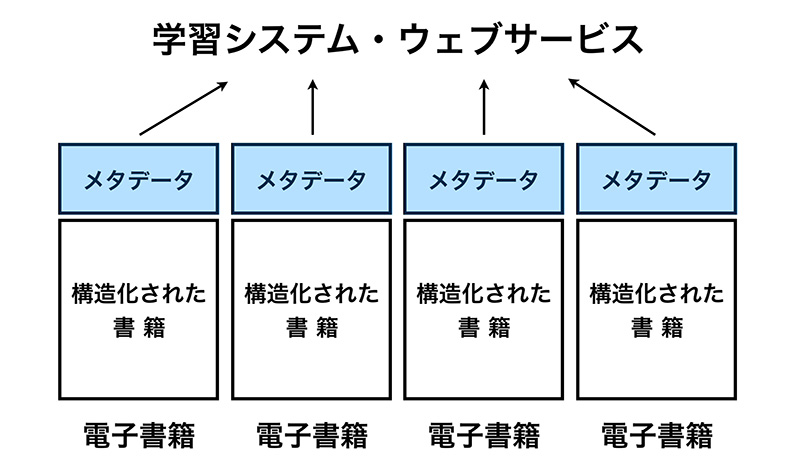
今回のテーマは「マシンリーダブルなデータ」です。コンピュータープログラムが、コンテンツの中身を理解できると、何が変わるのか、私たちの仕事や生活にどのような影響があるのか?
インターネットで最も身近な「検索」サービスを取り上げ、具体的な事例を示しながら、お話していきたいと思います。
クローズドな世界であっても、オープンウェブとのパイプをつくっておく
O’Reilly Media(オライリーメディア)とPearson(ピアソン)が共同で提供しているサブスクリプションサービス「Safari Books Online」は、34,000冊以上の技術書やデザイン書の閲覧、そして、1,400のビデオ(チュートリアル、講演など)を自由に視聴することができます。
サブスクリプションサービスですから、ログインしなければ利用できないのですが、Google検索で電子書籍のページが表示される場合があります。下図は、Edge Animateというアプリケーションソフトで使われるJSONの例を調べるため、「Edge Animate .an JSON」と入力したときの検索結果です。Safari Books Onlineの中の電子書籍が表示されています。
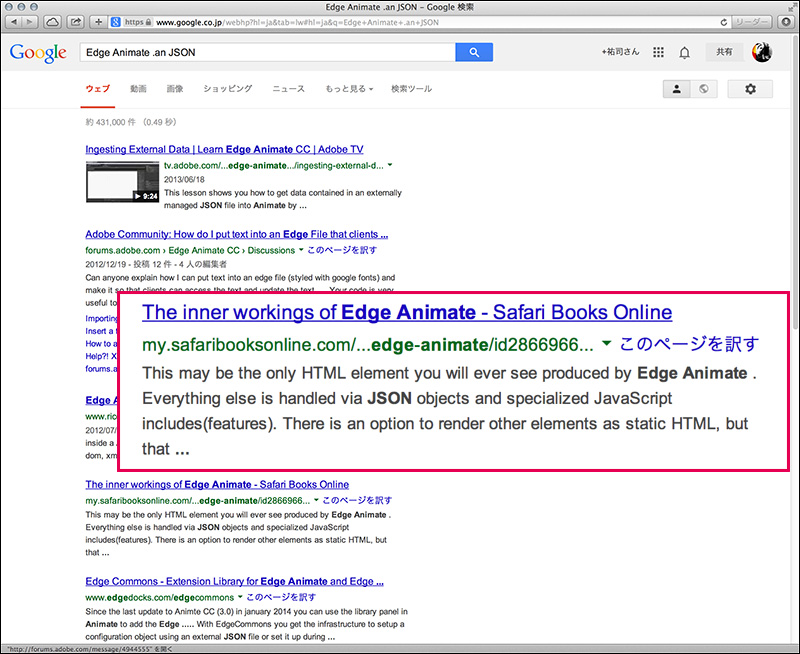
リンクをクリックすると、「Learning Adobe Edge Animate」という書籍の第一章の1ページが表示されます。知りたかったJSONの事例について書かれたページです。右上には「Free Trial」のボタンがありますので、トライアルモードで表示されていることがわかります(閲覧に制限があります)。
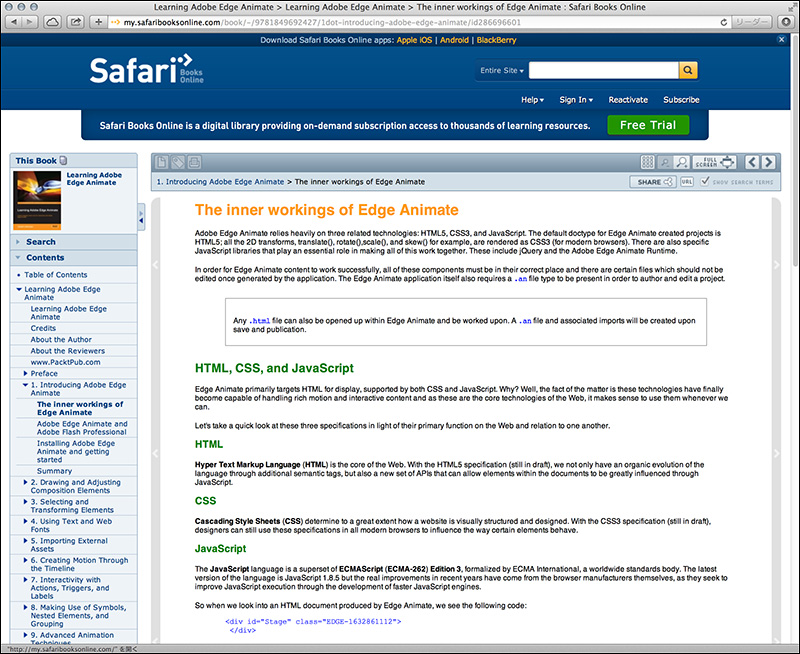
クローズドな会員制サブスクリプションサービスであっても、オープンウェブの検索で探せるという一例です。これがきっかけで、Safari Books Onlineに興味を持ち、10日間無料のフリートライアルに登録する人が出てくるかもしれません。
このようなトライアルモードは、サブスクリプションモデルを導入するときの参考になります。

スマートフォンの急速な普及に伴い、「ウェブ検索」は日常生活の一部となり、今ではインターネットの技術であることを意識する必要もありません。
GoogleやYahoo!、Bingなどの検索サービスも、セマンティック技術を利用したアンサーエンジンとして進化しており、検索結果のページも、イメージ、動画を含むウェブマガジンのようなレイアウトで表示されるようになってきました。特に、ナレッジグラフや(構造化データを参照して表示する)リッチスニペットなどは、イーブックデベロッパーの方々も理解しておいたほうがよいでしょう。
1回の検索でさまざまな関連情報を提供、進化するナレッジグラフ
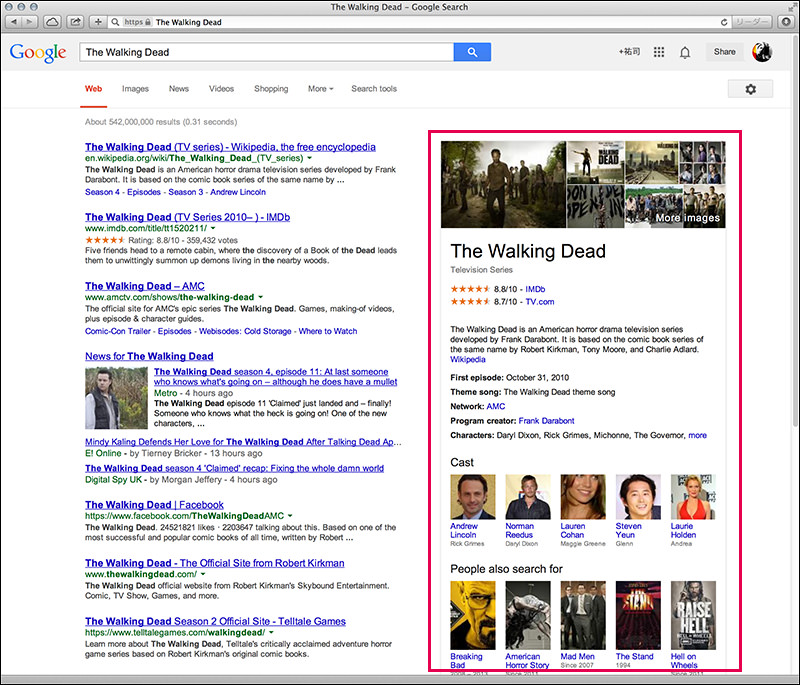
Google検索でちょっとした実験をしてみます。話題のテレビ番組を検索して、どのようなページが表示されるのか確認したいのです。例えば、「The Walking Dead」と入力すると下図のような検索結果になります。注目してほしいのは、右側の情報です。「ナレッジパネル」と呼びます。
Googleが2012年5月16日に発表した知識ベースの検索技術「ナレッジグラフ(Knowledge Graph)」の機能の一つです。
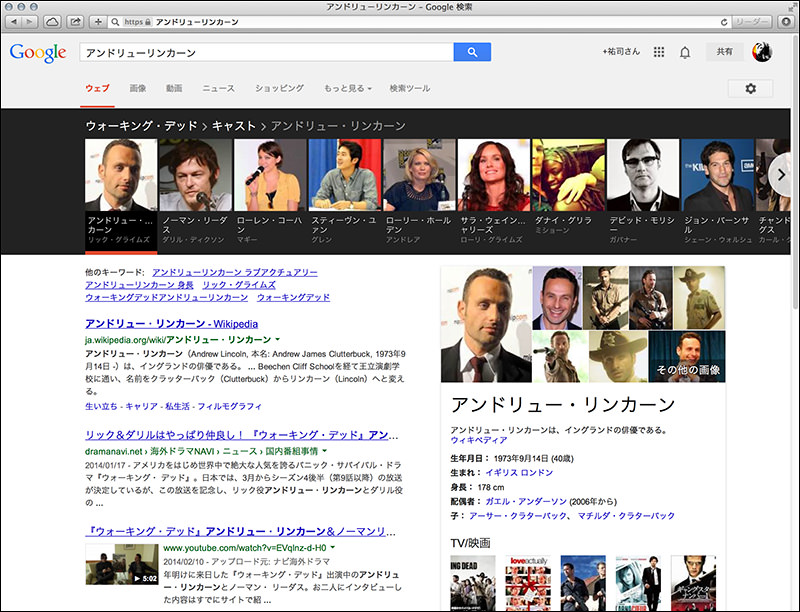
Cast(キャスト)の箇所に主人公リック役のアンドリュー・リンカーン(Andrew Lincoln)が表示されていますので、クリックします。すると、検索結果の上部にキャストの一覧が追加されます。「ナレッジカルーセル」と呼びます。右側には、アンドリューのプロフィールが表示されています。
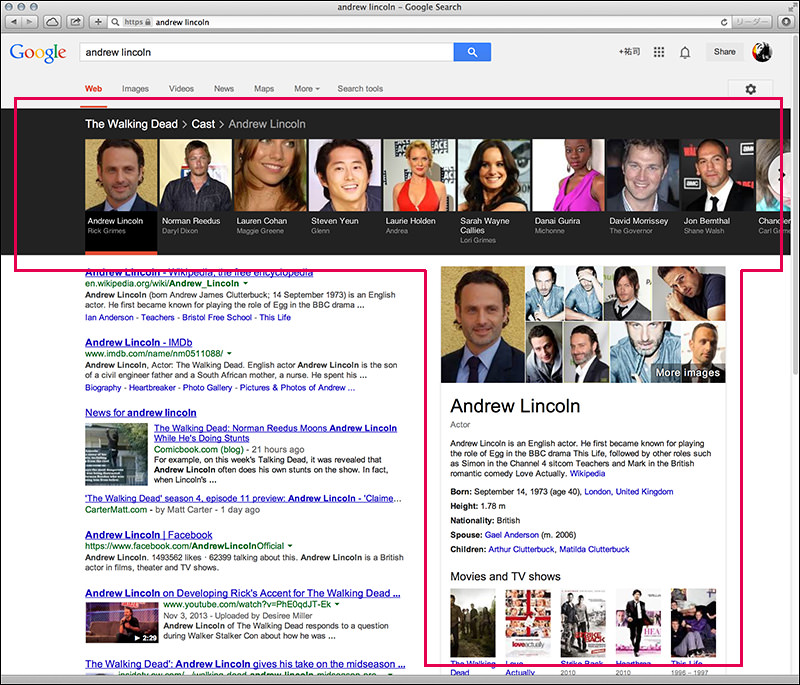
今度は、ナレッジカルーセルからノーマン・リーダス(Norman Reedus)を選びます。プロフィール欄には、他の出演作が表示されていますので、「Blade II」という映画をクリックしてみます。
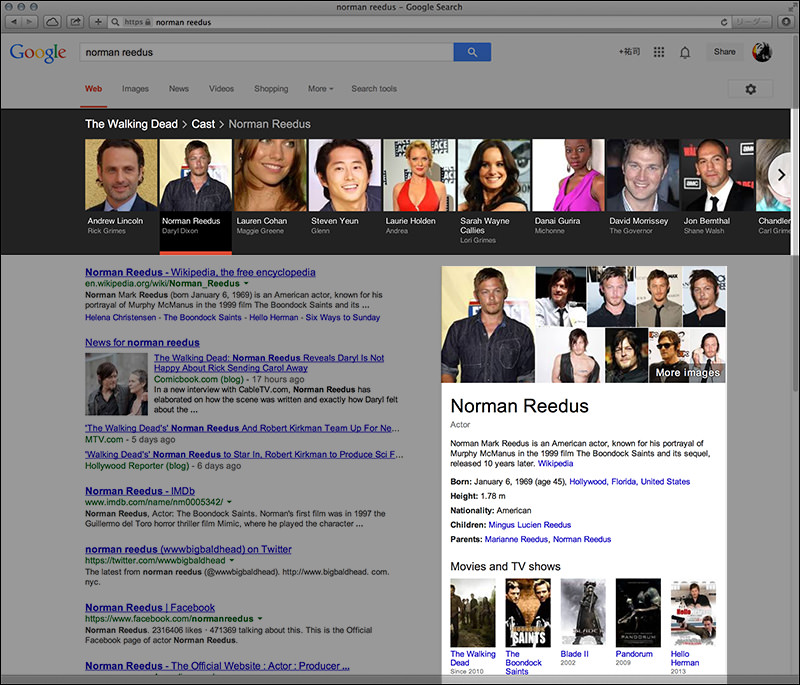
ナレッジパネルの内容が変わりました。「Blade II」の情報が表示されています。
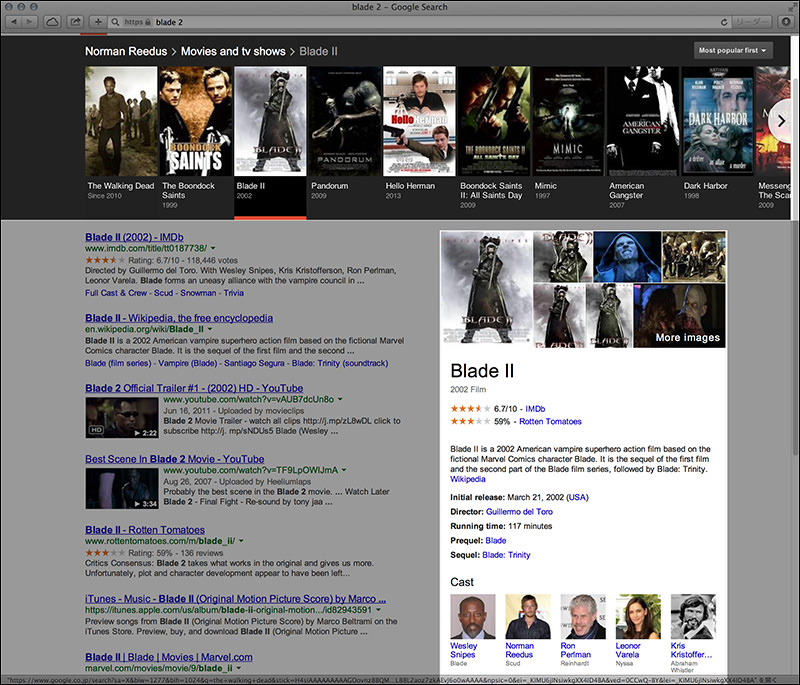
言語が「日本語」の場合もほぼ同じ情報が表示されます。
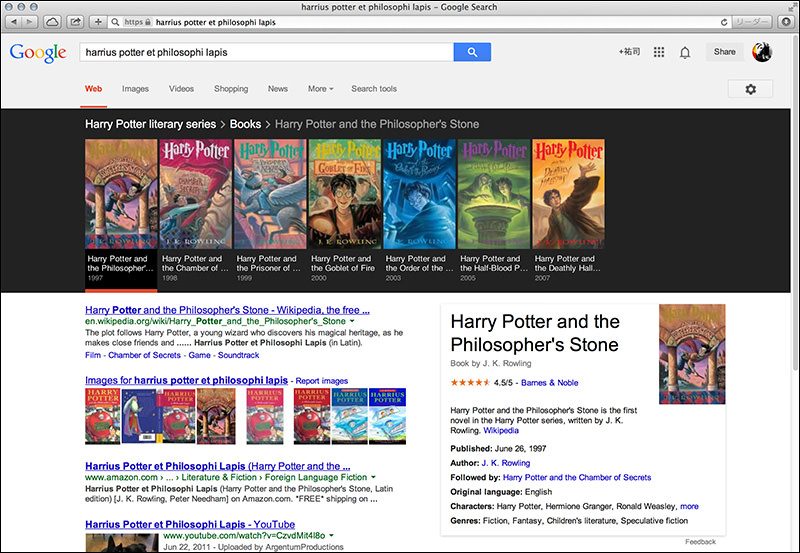
テレビドラマや映画以外でも確認してみましょう。下図は、ハリーポッター(Harry Potter Series)とブリトニー・スピアーズ(Britney Spears)、書籍と人物の検索です。
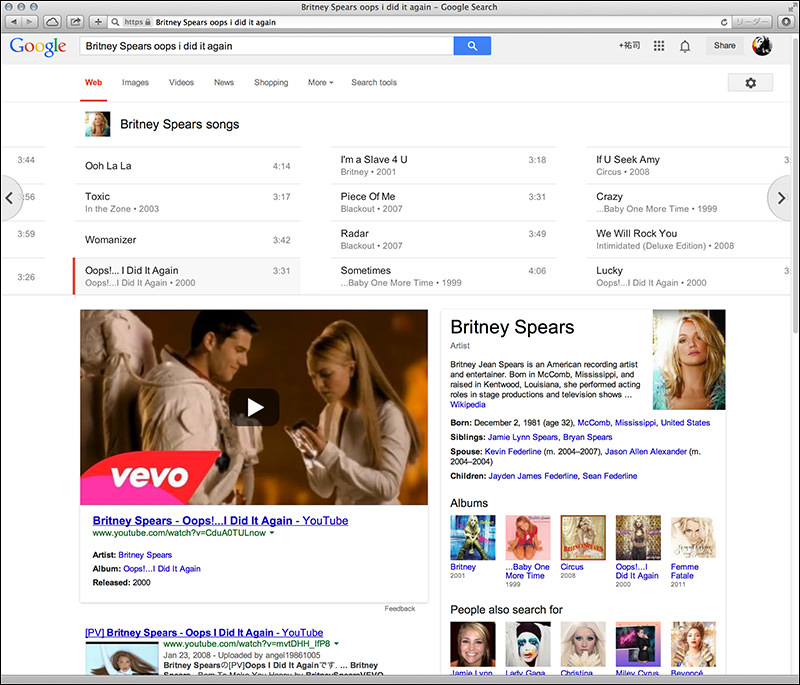
ブリトニー・スピアーズの場合は、「Oops!… I Did It Again」という曲をクリックし、上部に他の曲を表示させました。マウスを左右にドラッグして選択することが可能です。曲名をクリックすると、YouTubeの公式チャンネルで公開されているPVが表示される仕組みになっています(言語が日本語でも同様)。
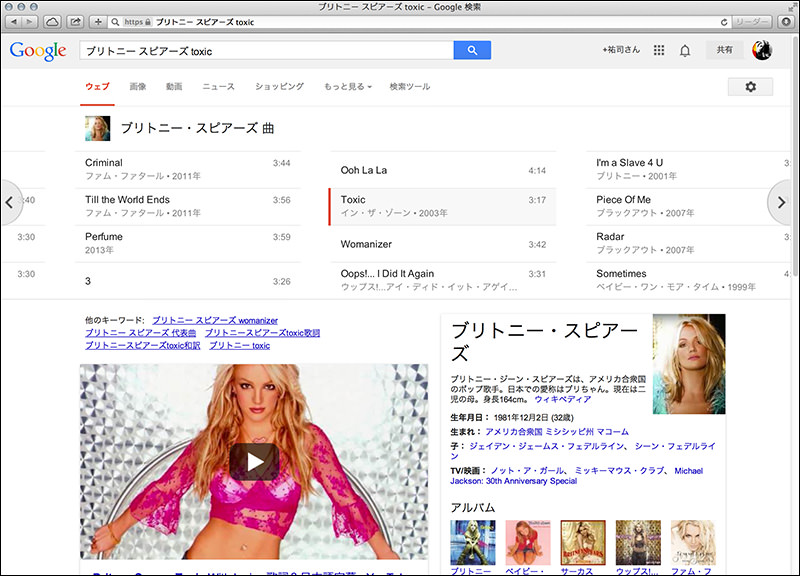
下図は「東京ディズニーシー」の検索結果です。ナレッジパネルには、地図や所在地、開園、面積などの情報が表示されています。また、上部にはナレッジカルーセルが表示されており、他の利用者が検索した関連キーワードがサムネイル付きで並んでいます。
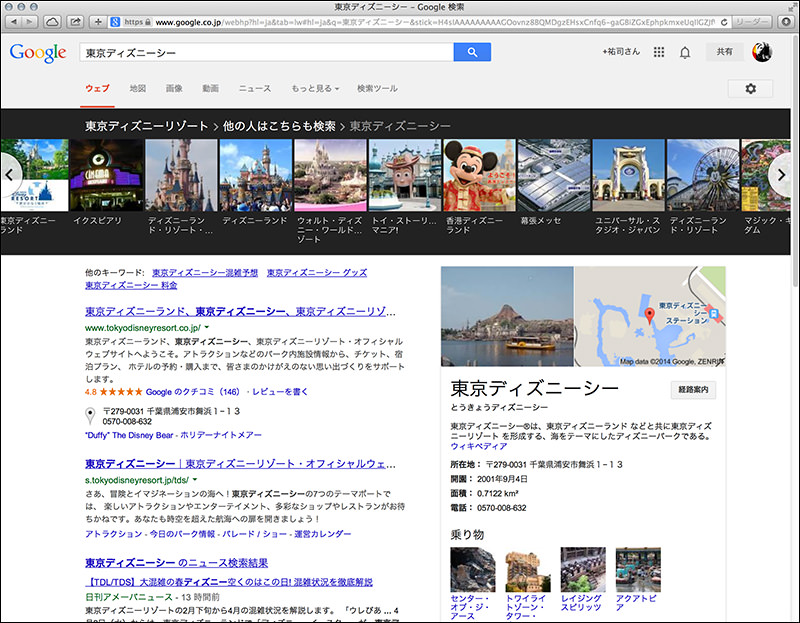
ナレッジグラフは、入力されたキーワード(文字列)を含むウェブページではなく、蓄積されている5億以上の「存在(entity)」を見にいきます。今までの検索技術とは大きく異なることがイメージできると思います。偶然に(自分にとって)価値あるものを発見するセレンディピティ(Serendipity)のトリガーになり得る仕組みだといえるでしょう。
また、ウェブの標準技術を策定しているW3C(ワールド・ワイド・ウェブ・コンソーシアム)が提唱している、人間の「感情」に関する情報を扱うマークアップ言語「Emotion Markup Language (EmotionML) 1.0」なども興味深い技術です。「Speech Synthesis Markup Language (SSML)」と組み合わせることで、感情を音声合成で表現することも可能になります。
これらの最先端技術は、まだ縁遠いものかもしれませんが、新しいアイデアを形にしていくときの良質なヒント集です。「ウェブ」の未来を考えることで、今までにない「コンテンツと技術のユニークな組み合わせ」を発見できるかもしれません。
参考:
テクニカルリード、シャシ・タークル(Shashi Thakur)氏の解説
Googleでは実世界での情報のつながりをナレッジグラフという方法で体系づけようとしています。
ナレッジグラフでは、実世界の物についての情報を収集します。人物、書籍、映画など、さまざまなタイプの「物」です。たとえば有名人なら誕生日、身長など、その人に関する情報を集めます。その人物を、ナレッジグラフ内の関連する情報とつなげることもできます。
プロダクトマネージャー、エミリー・モクスリー(Emily Moxley)氏の解説
あなたが疑問に思ったことを、既に他の人がGoogleで検索しているかもしれません。他の人がナレッジグラフで有益と感じた情報をベースにして、そこから検索を始められるのです。
プロダクト・マネージメント・ディレクター、ジョアナ・ライト(Johanna Wright)氏の解説
人類の知恵を蓄積したウェブで人々が何を検索しているかを見れば、データベースにどんな情報を含めるべきかがわかります。
Introducing the Knowledge Graph
構造化データで自分のサイトをウェブの「知」に加える
Googleが、2009年11月から開始した「リッチスニペット(Rich Snippets)」もウェブの情報を有効に活用するための技術です。検索結果に説明文などの属性情報、レビューなどの評価情報を表示してくれます。
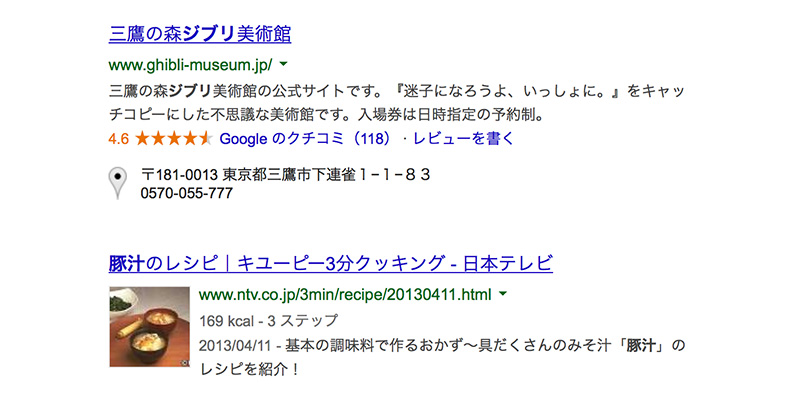
検索エンジンは、コンテンツの中の作品名や人物名、イメージ(画像)、レビューなどの意味付けされた構造化データを参照して、リッチスニペットを表示しています。検索キーワードに関連したさまざまな情報(画像や映像を含む)を一覧できるため、利用者にとっては利便性が向上し、情報発信者にとっても露出度がアップするという利点があります。
構造化データは、適切なマークアップによってつくられます。マークアップは「microdata(マイクロデータ)」や「microformats(マイクロフォーマット)」、「RDFa」などの仕様が使えます。Googleは、microdataを推奨していますが、他の2つの仕様もサポートしています。ただ、これから構造化を始めるのであれば、Googleが推奨しているmicrodataを使ったほうがよいでしょう。
参考:
2011年6月2日、Google、Yahoo!、Microsoft(Bing)の3社は、構造化データのマークアップ方法やプロパティを共通化するため、共同で開発・サポートしていくための「schema.org(スキーマドットオーグ)」イニシアティブを発足。構造化データのマークアップには「microdata(マイクロデータ)」が採用されました。

参考:
引用:
RDFa や microformats ではなく、microdata が採用された理由は何ですか。
これまで Google では、構造化データ マークアップの規格として、microdata、microformats、RDFa の 3 つをサポートしてきました。これら 3 つの異なる形式のうちのいずれかをウェブマスターが選択する形をとっていましたが、このたび、schema.org の形式として 1 つを選ぶことが決定しました。また、形式を統一することでデータを利用する検索エンジン間の一貫性が向上します。既存の規格のうちどれが最適かという点は意見が分かれるところですが、RDFa の拡張性と microformats の簡易性の中間でバランスがとれているという理由から、microdata の採用が決定しました。
昨年の10月21〜25日、シドニーで開催された「ISWC(International Semantic Web Conference:インターナショナル・セマンティックウェブ・カンファレンス)2013」で、Googleのラマナサン・グハ氏が講演しました。
ラマナサン・グハ氏は、schema.orgの設立から深く携わってる人物です。
Light at the End of the Tunnel(55分19秒)
参考:
schema.orgは、Pinterest(ピンタレスト)の「Rich Pins」でも採用されています。映画、レシピ、記事、製品、プレイスの5つのリッチピンに対して、構造化データのマークアップを実行します。
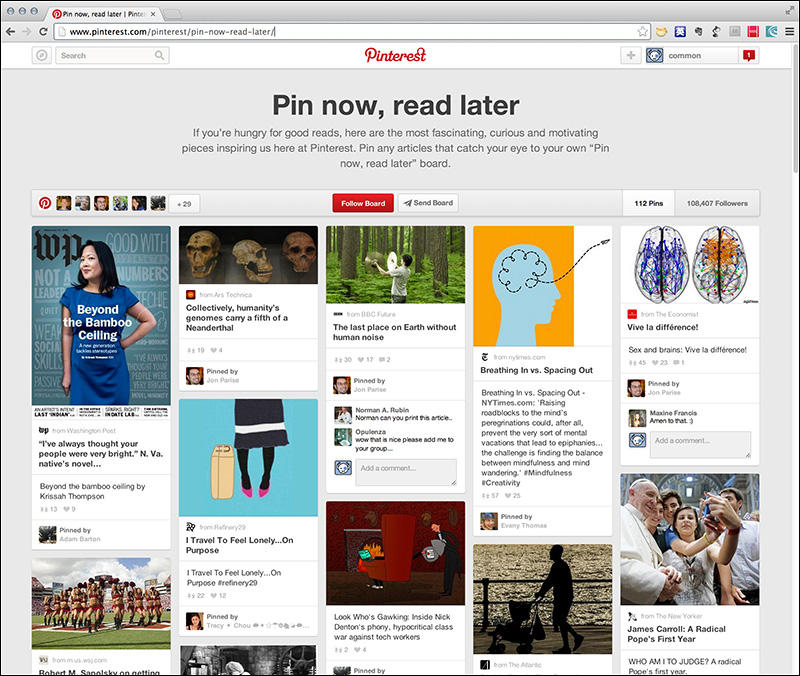
Microdataでマークアップする方法と、データハイライターでタグ付けする方法
構造化データのマークアップには、前述したとおりmicrodataを使うことが推奨されています。
例えば、以下のようにマークアップすることができます。itemscope属性でmicrodataの使用を宣言し、itemtype属性でタイプを指定します(ここでは「Book」を指定)。情報の項目については、itemprop属性で記述していきます。
書籍の記述例:
<div itemscope itemtype=”http://schema.org/Book”>
<meta itemprop=”bookFormat” content=”EBook/EPUB3″ />
<img itemprop=”image” src=”http://admn.mobi/data/edge_animate_book-cover.jpg” />
<dl>
<dt>書籍名:</dt>
<dd itemprop=”name”>Adobe Edge Animate スタートガイド</dd>
<dt>著者名:</dt>
<dd itemprop=”author”>境祐司</dd>
<dt>本書の概要:</dt>
<dd itemprop=”description”>HTML5によるアニメーション制作ツールの基礎をマスターする</dd>
<dt>ページ数:</dt>
<dd itemprop=”numberOfPages”>216ページ</dd>
<dt>ISBN-13:</dt>
<dd itemprop=”isbn”>978-4774159386</dd>
<dt>出版社:</dt>
<dd itemscope itemprop=”publisher” itemtype=”http://schema.org/Organization”>技術評論社</dd>
</dl>
</div>
参考:
- Book – schema.org | Thing > CreativeWork > Book
2013年2月、Googleウェブマスターツールに「データハイライター」が追加されました。このツールを使用すると、マークアップの作業を省くことができます。マウスで選択しながらタグ付けし(メニューからタグを選ぶだけ)、構造化データのパターンをGoogleに通知すればよいのです。つまり、schema.orgのボキャブラリやMicrodataの知識がなくても、構造化データのマークアップと同様のタグ付けが実行できるということです。
もちろん、直接マークアップする方が、意味付けもこまかく制御できるのですが、専門知識を持たない人でも作業可能になったことは(セマンティックマークアップを促進させることにもつながるため)大きな前進だといえるでしょう。
データハイライターを使ってページ上の構造化データを通知する
初めて使う場合は、ジャック・メンツェル氏(Googleプロダクト・マネージメント・ディレクター)による解説ビデオを見ておくと概要を理解できます。以下に、ポイントのみ列挙しておきます。
Introduction to Data Highlighter
- データ ハイライターは、ページ上の構造化データをGoogleに簡単に通知するツール
- Googleは、この構造化データを利用して、検索結果にリッチスニペットなどを表示している
- 例えば、あるページにイベント情報があり、Googleが正しく理解できれば、検索結果にイベントの場所や時間なども表示することができる
- データ ハイライターを使えば、マークアップせずに、ページ上の構造化データをGoogleに通知することができる
参考:
データ ハイライターがサポートしているデータのタイプは以下のとおりです(2014年2月26日現在)。
タグのかっこ内には対応するschema.orgのプロパティを表記しています。
記事
schema.orgの「Article」のプロパティに対応
- タイトル(name)
- 執筆者(author)
- 公開日(datePublished)
- 画像(image)
- カテゴリ(articleSection)
- 平均評価(aggregateRating)
イベント
schema.orgの「Event」のプロパティに対応
- タイトル(name)
- 日付(startDate および endDate)
- 場所(place)
- 画像(image)
- 公式 URL(url)
- カテゴリ(additionalType)
- パフォーマー(performer)
- チケット(offer)
地域のお店やサービス
schema.orgの「LocalBusiness」のプロパティに対応
- 名前(name)
- 住所(address)
- 電話(telephone)
- 営業時間(openingHours)
- カテゴリ(additionalType)
- 画像(image)
- URL(url)
- 平均評価(aggregateRating)
- クチコミ(review)
映画
schema.orgの「Movie」のプロパティに対応
- 名前(name)
- 画像(image)
- 監督(director)
- 脚本家(author)
- 出演(actor)
- 公開日(datePublished)
- ジャンル(genre)
- MPAAの評価(contentRating)
- 上映時間(duration)
- 公式 URL(url)
- 平均評価(aggregateRating)
- レビュー(review)
商品
schema.orgの「Product」のプロパティに対応
- 名前(name)
- 画像(image)
- 料金(offer)
- 商品 ID(productID)
- 平均評価(aggregateRating)
- レビュー(review)
レストラン
schema.orgの「Restaurant」のプロパティに対応
- 名前(name)
- 住所(address)
- 電話(telephone)
- 営業時間(openingHours)
- 料理の種類(servesCuisine)
- 画像(image)
- URL(url)
- 予約の URL(acceptsReservations)
- メニューの URL(menu)
- 平均評価(aggregateRating)
- クチコミ(review)
ソフトウェア アプリケーション
schema.orgの「SoftwareApplication」のプロパティに対応
- 名前(name)
- 画像(image)
- カテゴリ(applicationCategory)
- リリース元(publisher)
- 公式 URL(url)
- ダウンロードの URL(downloadUrl)
- オペレーティング システム(operatingSystem)
- リリース日(datePublished)
- ソフトウェア バージョン(softwareVersion)
- 平均評価(aggregateRating)
- レビュー(review)
テレビ番組のエピソード
schema.orgの「TVEpisode」のプロパティに対応
- シリーズ名(partOfTVSeries)
- エピソード名(name)
- シーズン番号(partOfSeason)
- エピソード番号(episodeNumber)
- 画像(image)
- ディレクター(director)
- 出演(actor)
- 放送日(datePublished)
- 公式 URL(url)
- 平均評価(aggregateRating)
- レビュー(review)
構造化データを通知する手順:
[01]ウェブマスターツールの「検索のデザイン」から「データ ハイライター」を選びます。続けて、「ハイライト表示を開始」をクリックします。

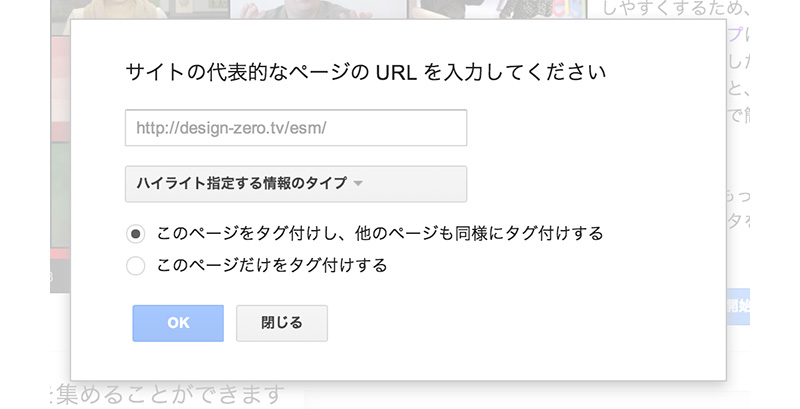
[02]「サイトの代表的なページのURLを入力してください」と記されたパネルが表示されます。
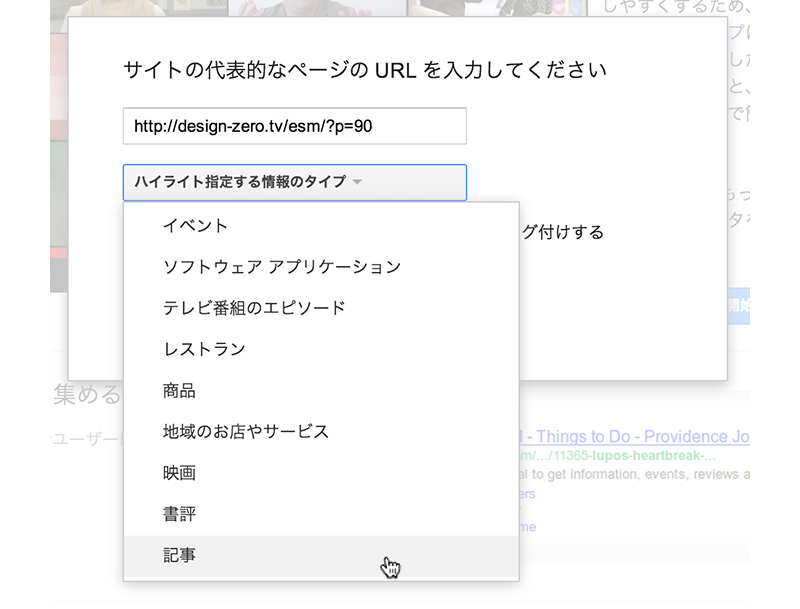
ここでは、電子書籍メディア論の連載記事のURLを入力、「ハイライト指定する情報のタイプ」は「記事」を選択、さらに「このページをタグ付けし、他のページも同様にタグ付けする」をチェックしました。
OKをクリックします。
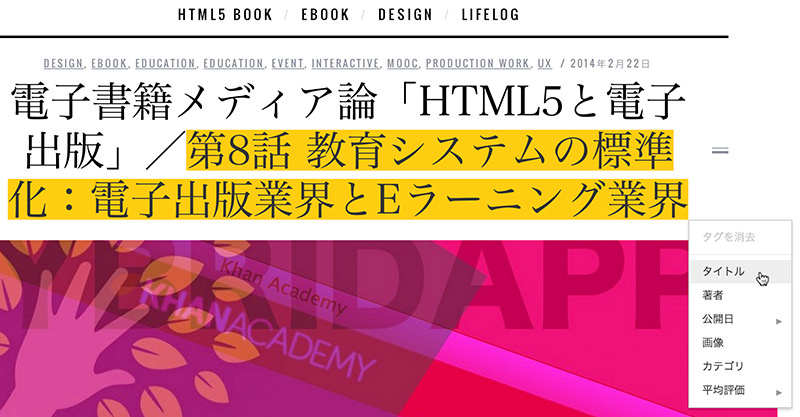
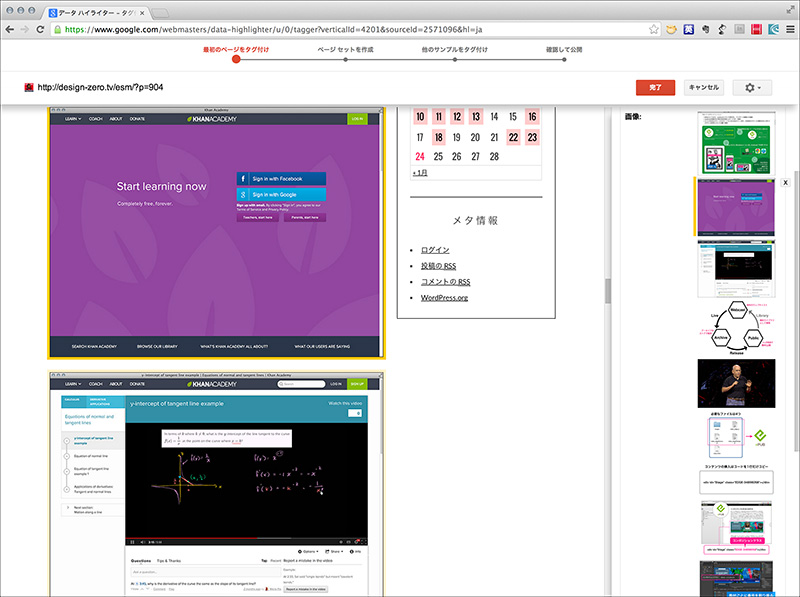
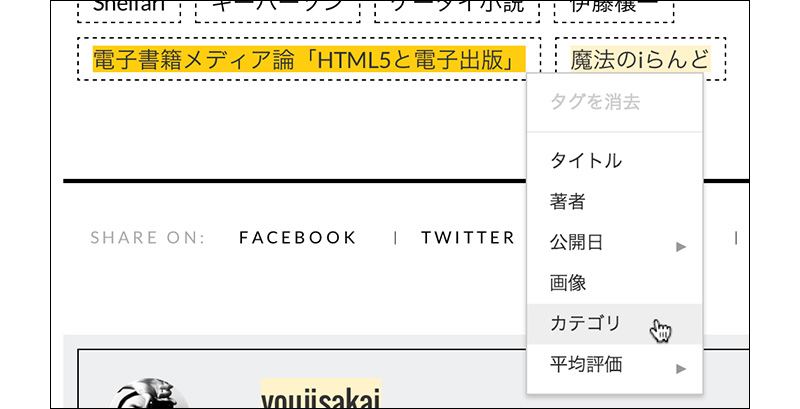
[03]Googleにキャッシュされている(指定したURLの)ページが表示されています。タグ付けは、とても簡単です。ドラッグでハイライトした後、メニューからタグを選びます。選択すると右側の「マイ データ アイテム」に表示されますので確認しましょう。
タイトルは必須ですが、見出しを選択して、メニューから「タイトル」を選ぶだけです。
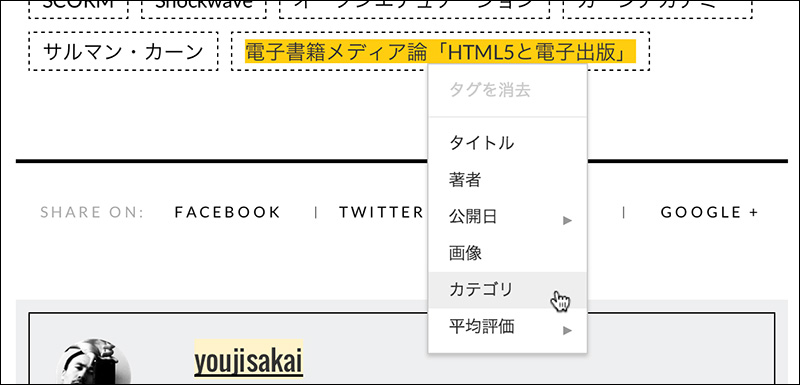
記事のタグ
- タイトル:記事のタイトル
- 著者:執筆した人の名前
- 公開日:公開された日付
- 画像:記事の中の画像
- カテゴリ:記事を分類するカテゴリ
- 平均評価:記事の評価
参考:
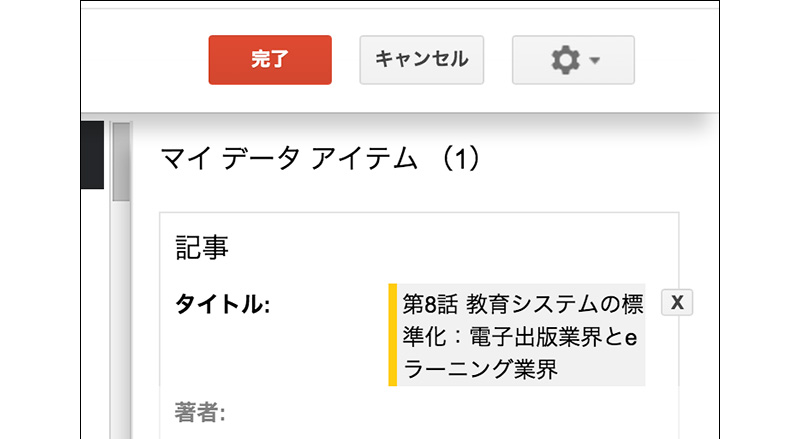
[04]ページの下部に投稿日を記載していますので、日付の部分をドラッグして、メニューから「公開日」→「日時」を選びます。
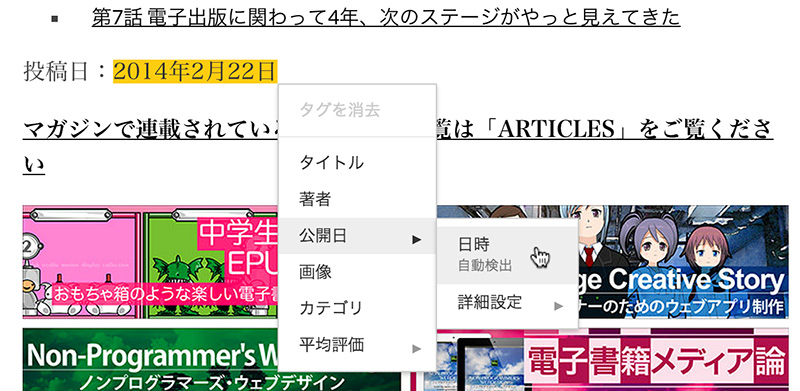
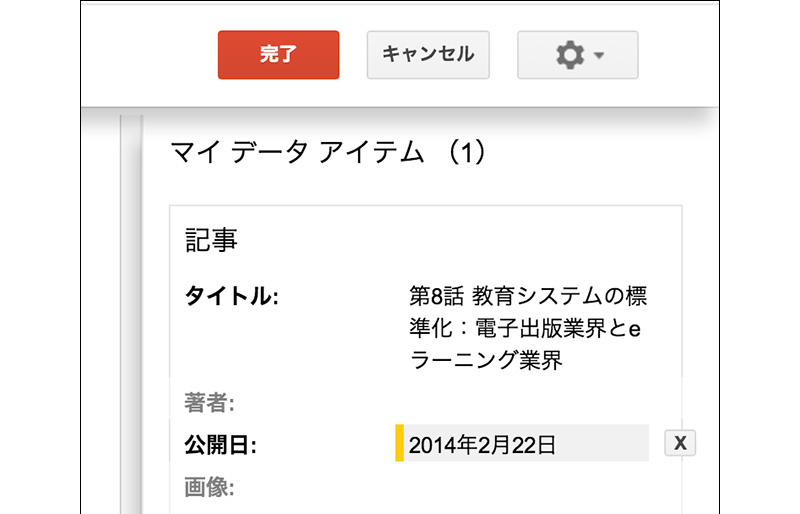
[05]画像をクリックして、メニューから「画像」を選びます。2つ目をタグ付けすると、ツールが自動的に残りの画像を選択してくれます。もし、誤りがあれば、「マイ データ アイテム」に表示されているサムネイルを削除します(右上の「×」をクリック)。
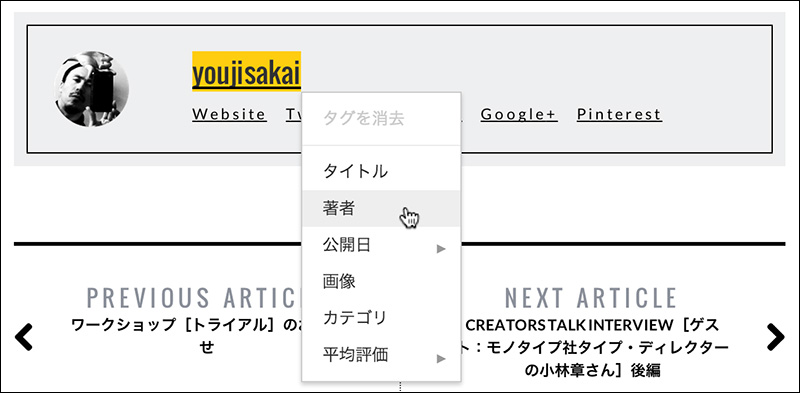
[06]タイトル以外のタグ付けは任意ですが、ここでは著者とカテゴリもタグ付けしておきます。
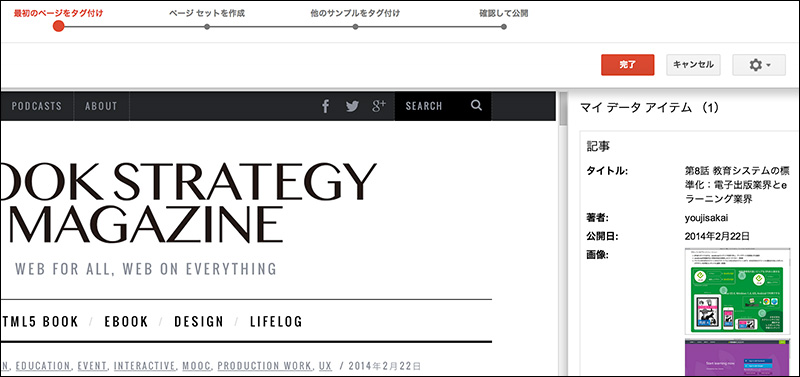
[07]ページのタグ付けが完了したら、「完了」をクリックして、「ページセットを作成」に進みます。処理が終わると「ページ セットの作成」のパネルが表示され、類似のページが検出されています。
ここでは、カスタムのページセットは作成せず、そのまま「ページセットを作成」をクリックします。
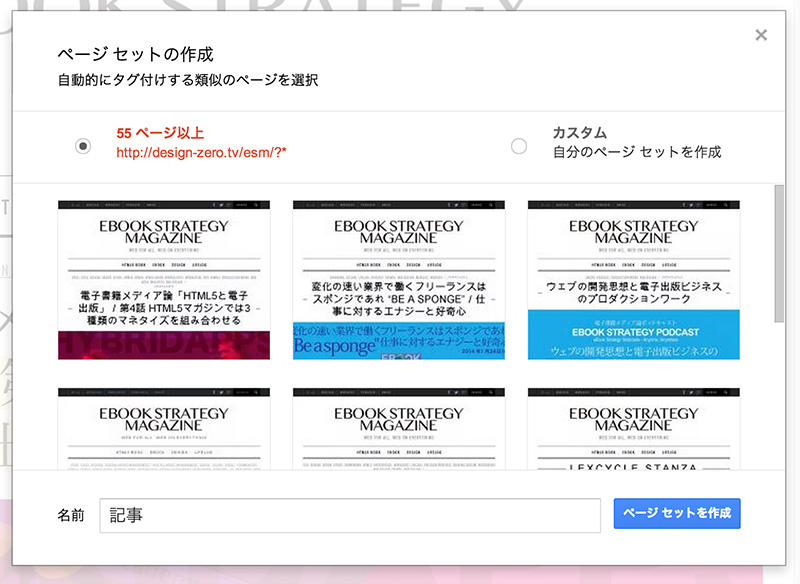
[08]処理が終わると、ページが表示されますので、自動的に追加されたタグが正しいかどうか「マイ データ アイテム」を見て、チェックしていきます。もし、間違いがあれば、修正します。警告のアイコンが表示されている項目は必ず確認してください。もし、誤りではない場合は、警告のアイコンを消去します。
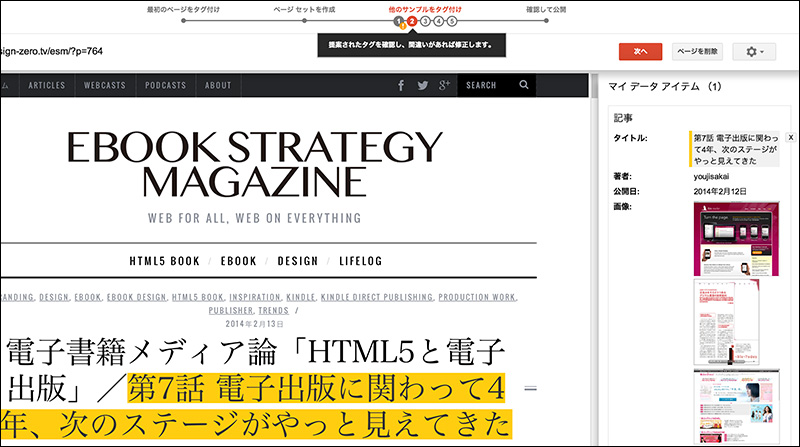
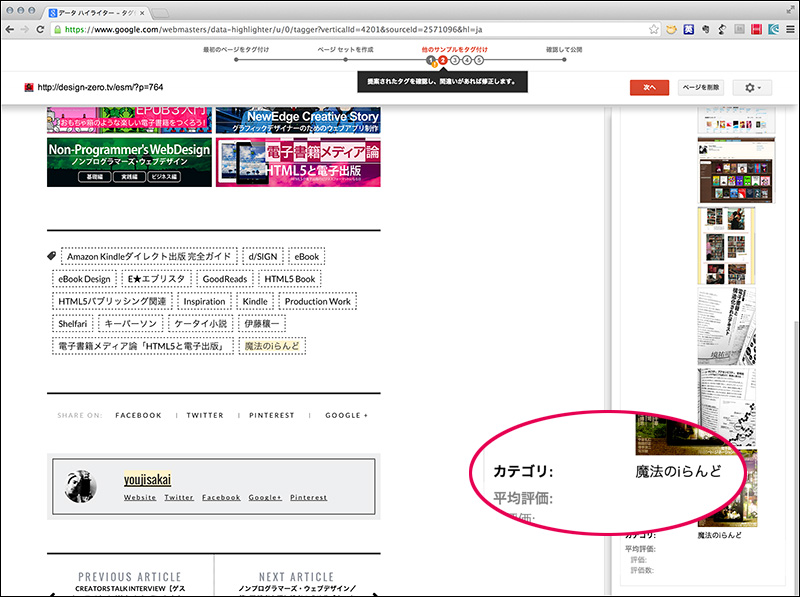
[09]カテゴリのタグが、関係のない「魔法のiらんど」になっていましたので、修正します。変更したいテキストをドラッグして、メニューから「カテゴリ」を選びます。
他に問題がなければ、右上の「次へ」をクリックしてください。
[10]次のページが表示されますので、同様に間違ったタグ付けを修正していきます。
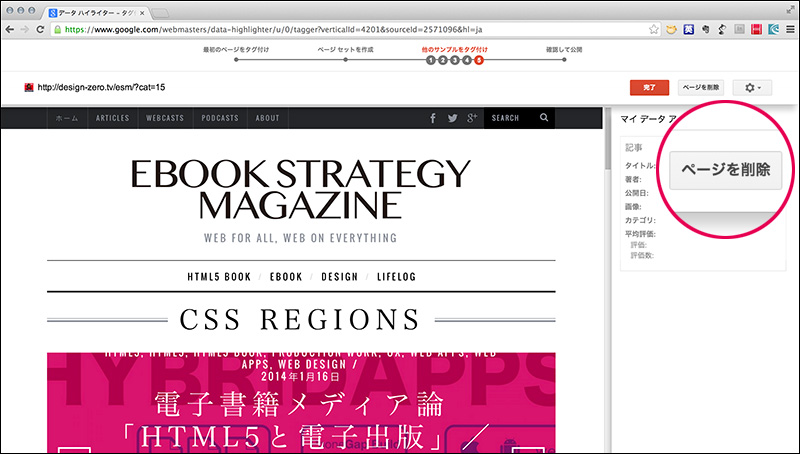
もし、記事以外の関係ないページが検出されていた場合は、「ページを削除」をクリックします。他のページが表示されます。

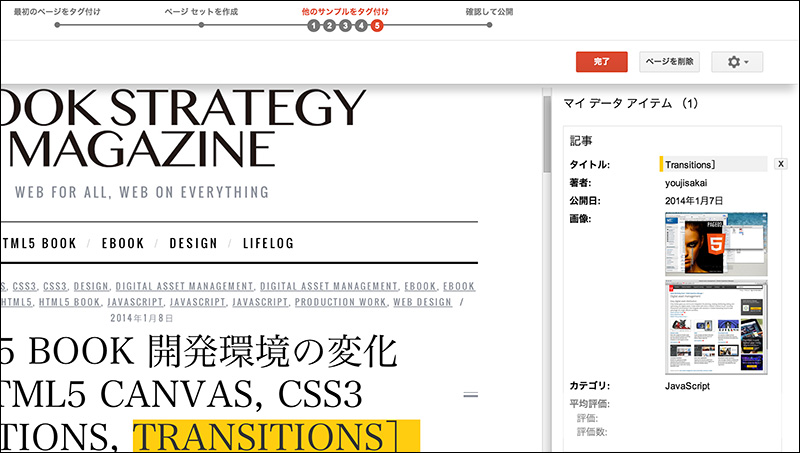
[11]タグ付けの修正が完了したら、右上の「完了」をクリックします。「さらに確認の必要があります」と表示された場合は、パターン学習を(マークアップの精度を)強化するために、同様の作業を続けます。
ここでは、ページごとに選択してきたカテゴリに類似性がない(記述されている場所に規則性がない)ため、警告が出ていたようです。検出されたページからカテゴリのタグを全て削除しました。
問題なければ「完了」をクリックします。
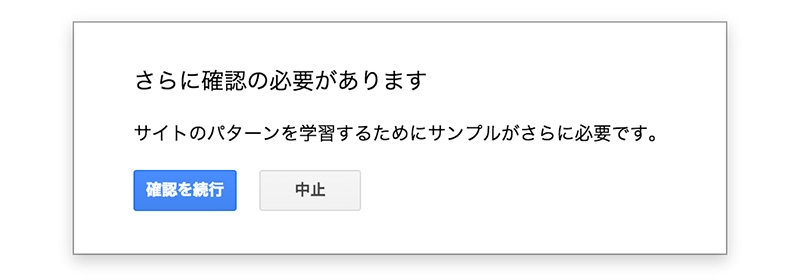
[12]「無造作に選ばれたページのサンプルを確認します。問題がなければGoogleに公開します。」とポップアップ表示されます。もし、誤りがあれば、左側の大きなサムネイルをクリックして編集画面に切り替えて、修正をします。
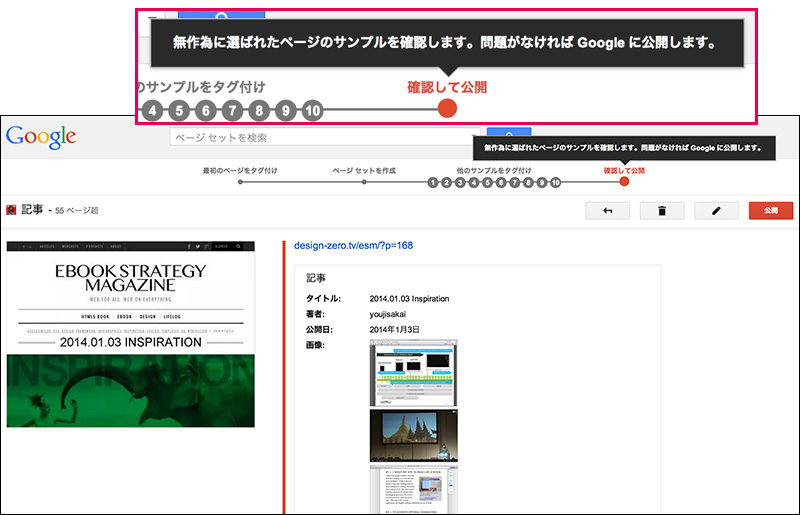
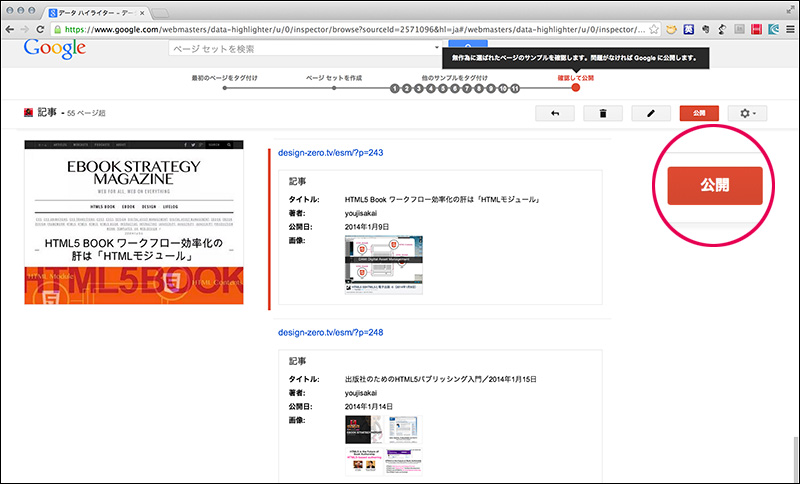
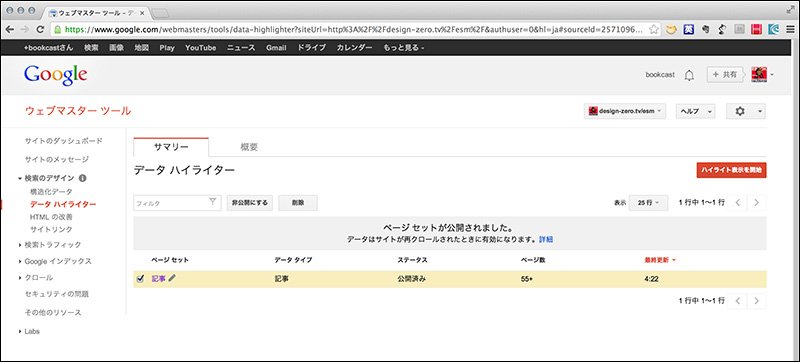
[13]確認できたら「公開」をクリックしてください。これで、ページセットが作成・公開されました。ページセットはいつでも編集することが可能です。もし、ページの内容を大幅に変更した場合は、タグ付けの修正が必要になりますので、必ずページセットを確認しておきましょう。
参考:
今回(第9話)のタイトルは「雑誌よ、ウェブの血となれ肉となれ! 構造化による知の体系」。
閉じたコンテンツより、フルオープンでセマンティックな媒体こそ、(検索エンジンやウェブサービスの力を借りて)面白いことができるのではないか、と思って付けたタイトルです。
HTML5マガジンの一番最初のプランニングで、「新しい雑誌、新しいウェブマガジンとは何か」を考えました。マルチメディア(映像や音声)やインタラクティブではないこと。これだけは明確でした。2010年のiPadブームのときに登場した拡張型の電子書籍や電子雑誌、素晴らしい作品が多かったのですが、新規性はあまり感じられなかったのです。
どちらかといえば、最先端アプリよりも、Flipboard(フリップボード)やZite(ザイト)のようなソーシャルニュースマガジンに可能性を感じていました。ただ、もう少し人間の「編集」要素が欲しいと思っていましたので、「ソーシャルニュースマガジン+まとめサイト」のようなイメージをずっと持っていたのです。
次回(第10話)、フルオープンでセマンティックな媒体の具体的なイメージについてお話したいと思います。
過去のエピソード:
- 第1話 公開終了
- 第2話 公開終了
- 第3話 エディトリアルデザイナーがウェブアプリ制作を担当
- 第4話 HTML5マガジンでは3種類のマネタイズを組み合わせる
- 第5話 電子出版界のペヨトル工房を目指せ!
- 第6話 電子書籍の寿命を読者にわかりやすく伝えること!
- 第7話 電子出版に関わって4年、次のステージがやっと見えてきた
- 第8話 教育システムの標準化:電子出版業界とeラーニング業界
投稿日:2014年2月25日
![6時間で学ぶ「Adobe Muse CC完全習得[基礎編]」発売日](http://design-zero.tv/esm/wp-content/uploads/2014/02/Muse_-Banner.jpg)
マガジンで連載されているコンテンツ一覧は「ARTICLES」をご覧ください

関連記事
 電子書籍メディア論「HTML5と電子出版」/第3話 エディトリアルデザイナーがウェブアプリ制作を担当
電子書籍メディア論「HTML5と電子出版」/第3話 エディトリアルデザイナーがウェブアプリ制作を担当 電子書籍メディア論「HTML5と電子出版」/第4話 HTML5マガジンでは3種類のマネタイズを組み合わせる
電子書籍メディア論「HTML5と電子出版」/第4話 HTML5マガジンでは3種類のマネタイズを組み合わせる ノンプログラマーズ・ウェブデザイン/第7回 ウェブの大海原から読者を探し確実に届ける仕組みと、電子出版専門の出版社をつくる方法
ノンプログラマーズ・ウェブデザイン/第7回 ウェブの大海原から読者を探し確実に届ける仕組みと、電子出版専門の出版社をつくる方法 ノンプログラマーズ・ウェブデザイン/第6回 電子書籍のウェブプロモーションを請け負うために実践してきたこと(1)
ノンプログラマーズ・ウェブデザイン/第6回 電子書籍のウェブプロモーションを請け負うために実践してきたこと(1) グラフィックデザイナーのためのウェブアプリ制作/第1回 インタラクティブ・グラフィックノベルをつくろう!
グラフィックデザイナーのためのウェブアプリ制作/第1回 インタラクティブ・グラフィックノベルをつくろう! 電子書籍メディア論「HTML5と電子出版」/第5話 電子出版界のペヨトル工房を目指せ!
電子書籍メディア論「HTML5と電子出版」/第5話 電子出版界のペヨトル工房を目指せ!

![Creators Talk Interview[ゲスト:モノタイプ社タイプ・ディレクターの小林章さん]](http://design-zero.tv/esm/wp-content/uploads/2014/02/Creators_Interview_Cover_20140212-600x400.jpg)